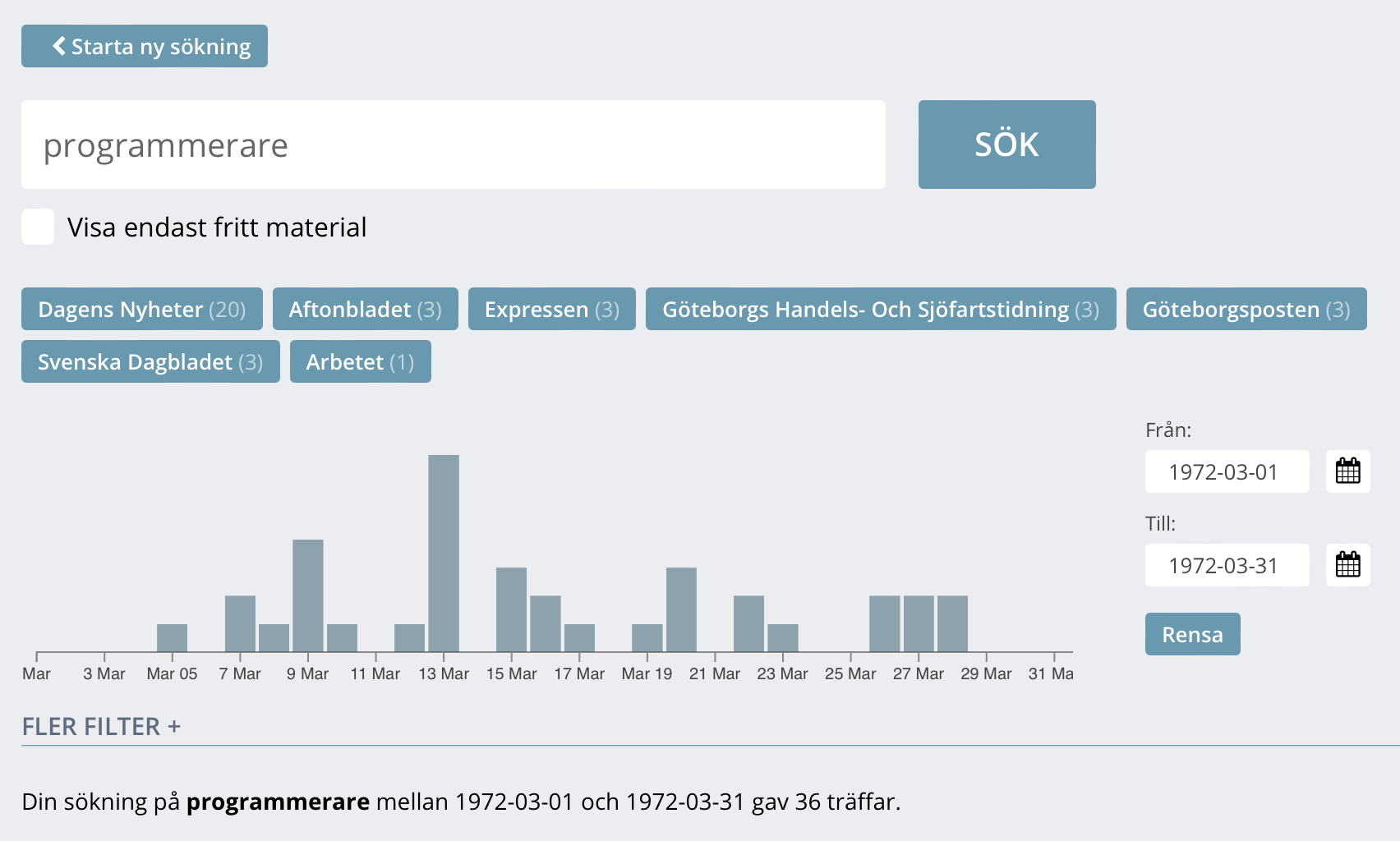
Jag älskar KBs tjänst Svenska dagstidningar och använder den flitigt. Det märks dock att KB lagt pengarna på att skanna dagstidningar, inte på att utveckla gränssnittet. Efter många år är nu en uppdaterad version på gång och det blir intressant att se vad som dyker upp i funktionsväg där.
I mitt doktorandprojekt (som jag tänkt skriva om här på bloggen allteftersom det framskrider) har jag bland annat tänkt använda platsannonser som historiskt källmaterial för att följa hur arbetsmarknaden för programmerare förändrades i takt med nya utbildningsmöjligheter. Och då är ju KBs tjänst en guldgruva för att hitta material.
Till min hjälp knåpar jag ihop olika skript för att hämta ut sökresultaten i strukturerad form. Till att börja med har jag gjort två ”bookmarklets”, dvs webbläsarbokmärken som istället för en URL innehåller javascriptfunktioner som hämtar ut information från den aktuella webbläsarfliken.
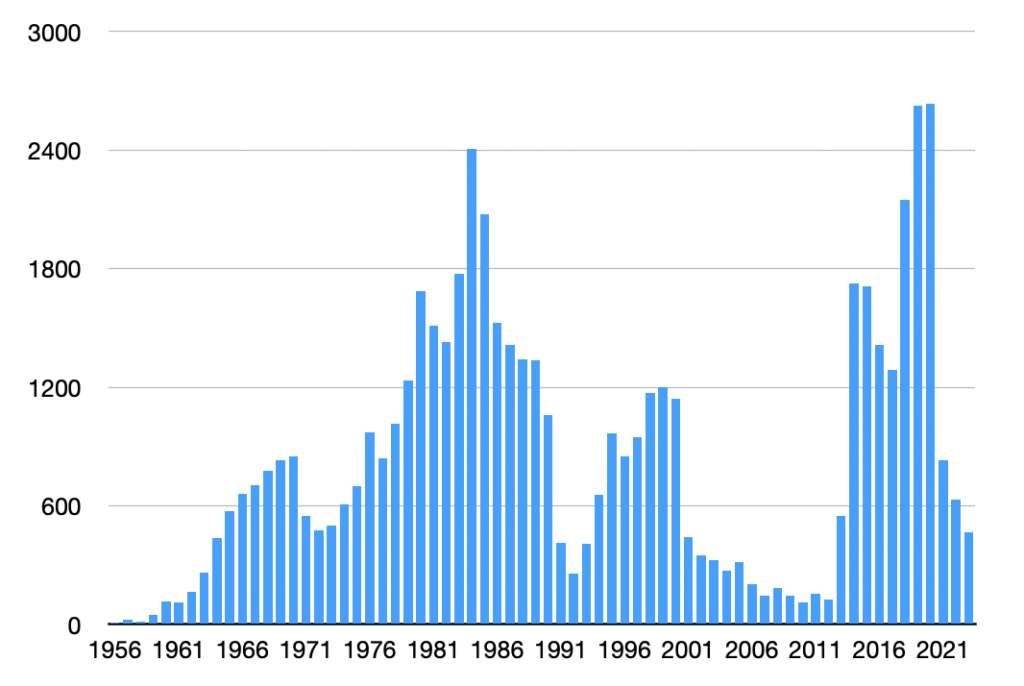
Antal träffar i tabellformat
Det första skriptet hämtar ut data från det stapeldiagram som visar antalet träffar. I mitt fall är jag intresserad av långsiktiga träffar och hämtar därför bara årtalet, men det är inga större förändringar som krävs för att istället hämta månad eller dag. Länk till skriptet. Åtminstone i Safari (har inte testat andra webbläsare) behöver jag ersätta mellanslag med %20 och ta bort radbrytningar för att det ska fungera; det är alltså följande textsnutt som läggs in istället för URL i bokmärket:
javascript:(function()%20{%20%20var%20csv%20=%20'year,count\n';%20%20var%20bars%20=%20document.querySelectorAll('.bar.year');%20%20bars.forEach(function(bar)%20{%20%20%20%20var%20dataDate%20=%20bar.getAttribute('data-date');%20%20%20%20var%20year%20=%20new%20Date(dataDate).getFullYear();%20%20%20%20var%20count%20=%20bar.getAttribute('data-count');%20%20%20%20csv%20+=%20year%20+%20','%20+%20count%20+%20'\n';%20%20});%20%20navigator.clipboard.writeText(csv);%20%20alert(csv);})();Istället för det grafiska stapeldiagrammet får jag då ut antal träffar per år i csv-format direkt i urklipp, vilket jag sedan kan klistra in i lämpligt kalkylark för vidare användning.
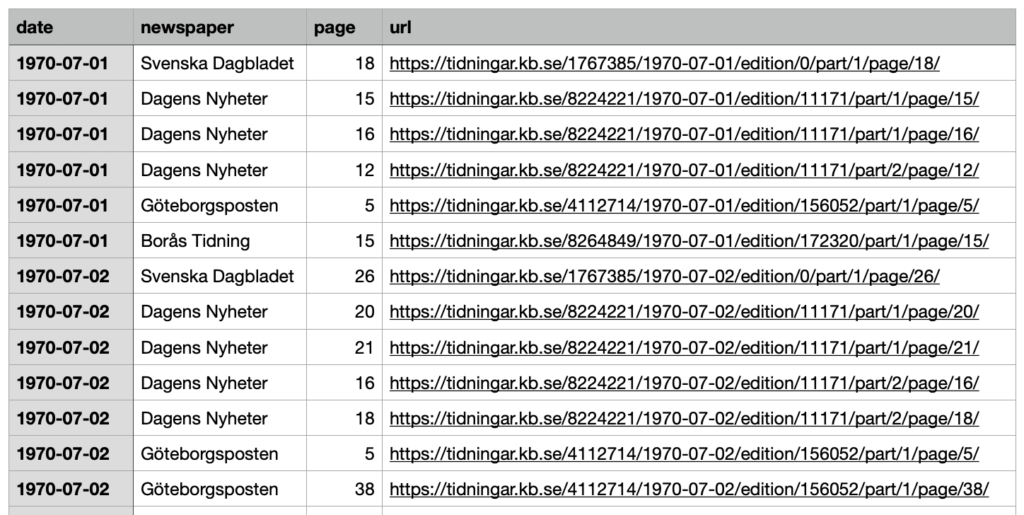
Information om sökträffar i tabellformat
Det andra skriptet hämtar resultatlistan i strukturerad form. Eftersom KB bara har rätt att visa själva de inskannade tidningssidorna på vissa utvalda platser (läs: KBs tidningsrum och några universitetsbibliotek) kan jag inte göra hela sökningen hemifrån. Däremot kan jag förbereda träfflistor, som jag sedan öppnar när jag väl är på plats på KB. Länk till skriptet.
Till att börja med är jag intresserad av om sökträffarna kommer från tidningarnas platsannonssidor eller inte. Eftersom platsannonserna oftast håller sig till vissa sidnummer kan jag grovsortera mina sökträffar redan i förväg.
Forskningsdata i strukturerad form
De här skripten är långt ifrån perfekta utan är mer att betrakta som tillfälliga knep för att komma vidare i utforskandet av källmaterialet. De går snabbt att modifiera beroende på vilken information jag vill hämta ut från mina sökningar i Svenska dagstidningar-tjänsten.
Det som behövs på längre sikt är ordentlig tillgång till den skatt av metadata som tjänsten Svenska dagstidningar innehåller. Just nu går det bara (åtminstone som intresserad allmänhet – det finns säkert forskare som blivit insläppta bakom kulisserna på KB, men än så länge är jag inte en av dem) att ta del av informationen via KBs egna gränssnitt. Istället borde KB tillgängliggöra informationen i form av strukturerade data, allra helst genom ett API. På så sätt blir det lättare för forskare att använda de skannade dagstidningarna.
Uppdatering: den alltid briljante Albin Larsson påpekar att det faktiskt finns ett JSON-API! Dock inte utannonserat eller dokumenterat. Men genom att haka på ”/api/json/” innan söksträngen levereras resultaten som JSON (exempelsökning) – vilket såklart gör det enklare att hämta hem data. Nya uppdaterade skript kommer inom kort!
Det här anknyter förstås till det jag och Åsa M. Larsson skrev om i Lychnos 2022: Hur FAIR är svensk digitiserad kulturarvsdata idag? Där går vi igenom nuläget hos de större plattformarna för digitalt publicerad kulturarvsdata (dit åtminstone jag hävdar att dagstidningarna räknas) och hur väl de uppfyller de så kallade FAIR-kriterierna för öppna data.